Milvus 入門
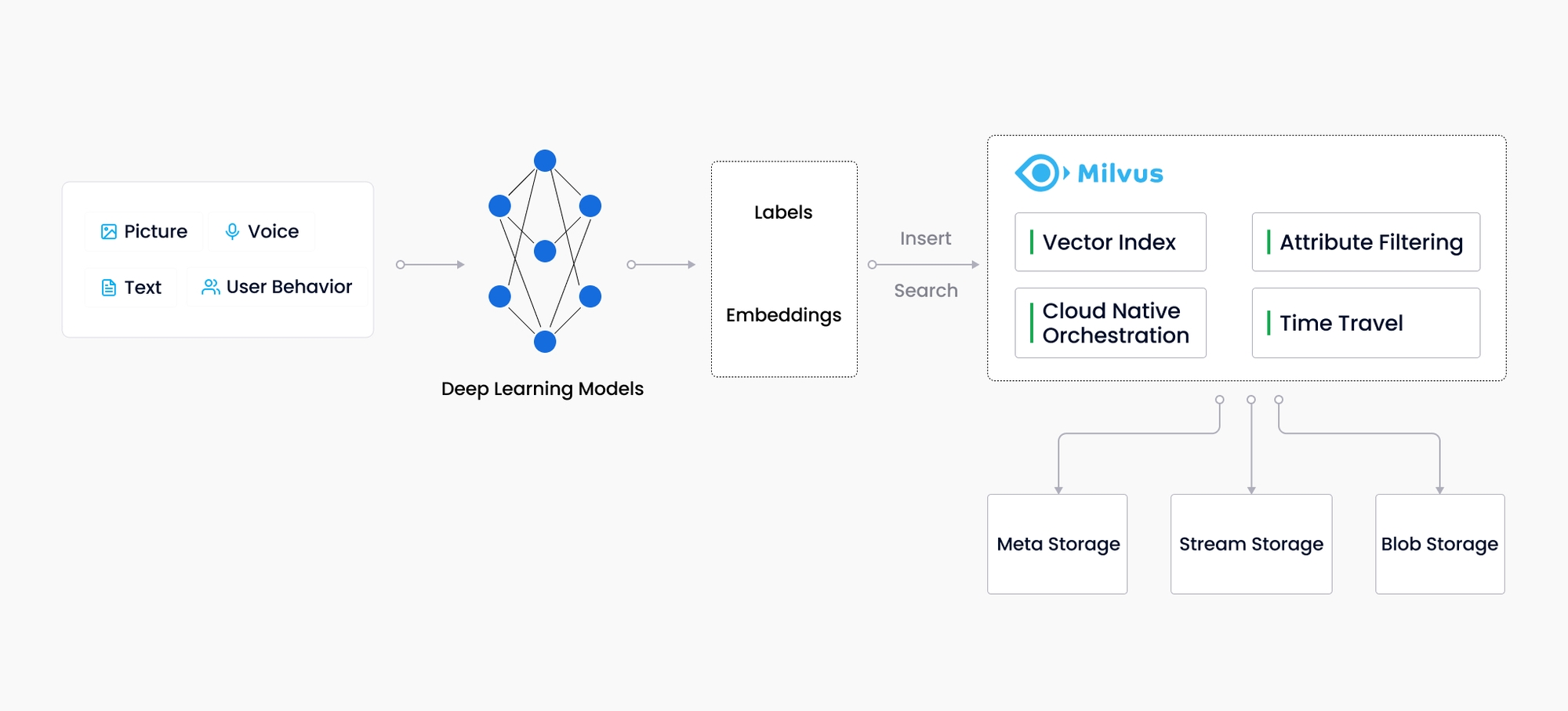
Milvus 創立於 2019 年,它只有一個目標:儲存、索引和管理由深度神經網路和其他機器學習(ML)模型所產生的龐大嵌入向量資料。是一個專門用於管理大量嵌入向量的開源向量資料庫。它可以對萬億規模的向量資料進行索引和搜尋。
與現有的、主要根據預先定義模式處理結構化資料的關聯式資料庫不同,Milvus 從一開始就是設計來處理從非結構化數據轉換而來的嵌入向量。
隨著網路發展,非結構化資料快速的成長例如郵件、論文、物聯網感測器數據,Facebook 照片,蛋白質結構等等都是非結構化的資料。為了讓電腦能夠理解和處理非結構化的資料,需要進一步將它們轉換為嵌入向量,而 Milvus 儲存和索引這些資料。
Milvus 能夠通過計算兩個向量之間的相似距離來分析它們的關聯性。如果兩個嵌入向量非常相似,則表示原始的數據來源也很相似。
核心概念
術語概覽
如果你是向量資料庫或相似度搜尋的新手,建議閱讀下面術語:
位元集(Bitset):一種資料結構,用於透過一系列的 0 和 1 來表示資料。每一個位元(bit)代表一個資料點。例如,將性別資訊表示為位元集,男性為 1,女性為 0。
1
2
3
4// 舉例來說,有一個表示性別的陣列
people = ['男', '女', '男', '女'];
// 以位元集表示則為
people = [1, 0, 1, 0];通道(Channel):Milvus 中用於資料傳輸的管道。包括 PChannel(用於傳輸日誌資料)和 VChannel(用於傳輸向量資料)兩種類型。
集合(Collection):Milvus 儲存資料的基本單位,相當於關聯式資料庫中的表格。
依賴項(Dependency):Milvus 運作所需的外部程式或服務,如 etcd、MinIO 或 S3、Pulsar 等。
實體(Entity):Milvus 中的一條資料記錄,由多個欄位組成,代表一個單獨的資料物件。例如,在一個會員資料表中,一筆會員資料即為一個實體。
欄位(Field):實體中的一個資料單元,可以是結構化資料(如數字、字串)或向量。在一個會員集合中,id、name、gender 等均為欄位。
日誌代理(Log broker):一種服務,負責管理 Milvus 的日誌資料,包括接收、儲存和傳輸日誌資料。
日誌序列(Log sequence):記錄 Milvus 中所有操作的日誌,包含資料的插入、刪除和更新等記錄。
日誌快照(Log snapshot):Milvus 日誌的一個特定版本,可用於在特定時間點恢復資料。
日誌訂閱者(Log subscriber):一種服務,用於接收 Milvus 的日誌資料,並可將日誌資料傳輸至其他系統進行分析或處理,有助於 Milvus 與其他系統的整合。
訊息儲存(Message storage):Milvus 用於儲存日誌資料的服務,可以是本地儲存或雲端儲存。
Milvus 叢集(Milvus cluster):用於部署大規模 Milvus 資料庫的環境。
Milvus 單機版(Milvus standalone):Milvus 的單節點部署版本,使用方便但擴展性有限,適合於開發和測試階段。
歸一化(Normalization):將向量轉換成具有相同範數(模)的過程,以提高向量相似度搜索的準確性。L2 歸一化是常用的一種歸一化方法。
非結構化資料 Unstructured data
非結構化資料包含圖片,影片,音檔,和自然語言。是一種沒有遵循預先定義模型或組織規範的資訊。這類型的資料估計佔據全世界數據的 80%,並且可以被轉換成 AI 和機器學習模型使用的向量資料。
嵌入向量 Embedding vectors
嵌入向量是非結構化資料的特徵抽象。例如電子郵件,物聯網感知器數據,Instagram 照片,蛋白質結構等等。
從數學的角度,嵌入向量是一個浮點數或二進制數據的陣列。現代嵌入技術可以將這些非結構化資料轉換成嵌入向量。
集合
首先,在 Milvus 中資料庫 Database 的概念和術語比較少用。因為 Milvus 是圍繞著集合 Collection 展開的,主要用 Collection 來組織資料。在 Milvus 我們不需要先建立一個資料庫的容器才建立集合。這和傳統關聯式資料庫 MySQL、PostgreSQL 不同。雖然你還是可以使用資料庫來隔離管理集合。
集合的角色類似於關聯式資料庫的資料表,注意雖然是資料表但在 Milvus 中集合不一定隸屬於某個資料庫。集合主要用來儲存和管理向量資料,每一個集合可以支援多個欄位 Field。這些欄位定義了儲存的資料型別,其中至少要有一個欄位是向量。
集合一致性(Collection Consistency)
在建立集合的時候,你可以設定一致性。由於 Milvus 原生雲端的設計,它作為一個分散式資料庫,設計就是允許多節點運行,也就是資料會分散儲存。此時的一致性影響的就是在不同節點同步資料的機制。
也就是說在分散式系統中,一致性模型定義了資料更新後,不同節點上資料一致性的保證程度。
- Strong :確保一旦寫入完成,後續所有的操作一定都是最新結果,無論操作發生在那個節點。這個設定提供了最嚴謹的保證。但可能需要犧牲一點性能作為代價。
- Session:同一會話中,客戶端可以看到自己寫入的更新確保讀取到自己寫入的最新資料。
- Bounded:這是一種折衷的模式,保證在特定條件或時間內讀取的操作會看到一致的資料。保證了一定程度資料是最新的同時耶考慮了效能和延遲。
- Eventually:這種設定允許不同節點之間暫時會不一致,但隨著時間推移最終所有節點一定是一致的資料。
集合的欄位和維度
- 欄位 Field:集合中的欄位類似於關聯式資料庫的欄位 Column。欄位定義資料類型,一個集合除了可以有向量欄位之外,也支援其他類型例如字串、整數等等。
- 維度 Dimension:針對向量欄位,維度指的是向量的長度,即向量中元素的數量。維度是事先定義的,例如,使用 OpenAI API 獲得的向量長度為 512,則該向量的維度是 512。全部儲存在該欄位的向量都必須擁有相同維度。
如果需要動態的變更集合的架構,如新增欄位那麼建立集合的時候需要啟用動態結構 - Enable Dynamic Schema Consistency。
向量相似性搜尋
向量相似性搜尋是將一個向量和資料庫中的向量進行比較的過程,目標是找到和查詢向量最接近相似的向量。類似最接近鄰居搜尋(ANN)搜尋演算法用來加速搜尋過程。如果兩個嵌入向量非常相似,這意味著原始數據來源也很相似。
向量搜尋和關聯資料庫的 SQL 語句不太一樣,它是根據提供的向量找出最相似最接近的向量。這個過程涉及將查詢轉換為向量,再用這個向量去查詢。在進行向量搜尋的時候涉及到幾個重要的概念:
- 搜尋向量(Query Vector)你希望查詢與之相似的向量
- 參數(Search Parameters)影響搜尋行為的參數,例如搜尋的演算法,回傳最相似向量的數量等等
- 相似度指標 (Similarity Metrics)衡量向量之間相似度的方法,例如歐式距離 L2,餘弦相似度等等
為何使用 Milvus?
- 進行搜尋大量向量資料時支援高性能
- 開發者優先的社區,提供多語言支援和工具
- 雲端的可擴展性和高可靠性
- 透過將標量過濾與向量相似性搜尋配對來實現混合搜尋
支援何種索引和標準(指標)?
索引是一種資料的組織單位,比喻來說就像是書本的目錄,少了目錄想找特定內容時會需要從頭翻遍整本書。因此您需要在搜尋或查詢已寫入的實體之前,宣告索引類型和相似度標準。若你沒有設定索引類型,Milvus 預設會使用暴力破解(Brute-force)搜尋,就是不使用任何索引的搜尋方法。它逐一比較所有向量與查詢向量的相似度。
索引類型
- FLAT:FLAT 適合搜尋小型、百萬級別資料上完全準確和精準的搜尋結構場景。
- IVF_FLAT:IVF_FLAT 是基於量化的索引,適合尋求準確性和查詢速度之間取得平衡的場景,另外還有一個 GPU 版本 GPU_IVF_FLAT。
- IVF_SQ8:基於量化的索引,適合尋求減少硬碟、CPU、GPU、記憶體消耗的情景。
- IVF_PQ:基於量化的索引,適合高速查詢,但犧牲準確性,另外還有一個 GPU 版本 GPU_IVF_PQ。
- HNSW:基於圖的索引最適合於對搜尋效率有高要求的場景。
相似度指標
在 Milvus 中,相似度指標(度量標準)是用來衡量向量之間的相似性。選擇一個好的距離度量指標可以明顯提高分類和聚類的性能。根據輸入資料的形式,選擇特定的相似度指標以獲得最佳性能。
廣泛用在浮點嵌入資料的指標包含:
- Euclidean distance L2 歐氏距離:這個指標通常用用於電腦圖像 Compute Vision 領域
- Inner product IP 內積:這個度量標準通常用於自然語言處理(NLP)領域。
另外,廣泛用於二進制嵌入資料的指標包含:
- Hamming 漢明距離:這個指標通常用於自然語言處理(NLP)領域。
- Jaccard 傑卡德相似度:這個指標通常用於分子相似性搜索領域。
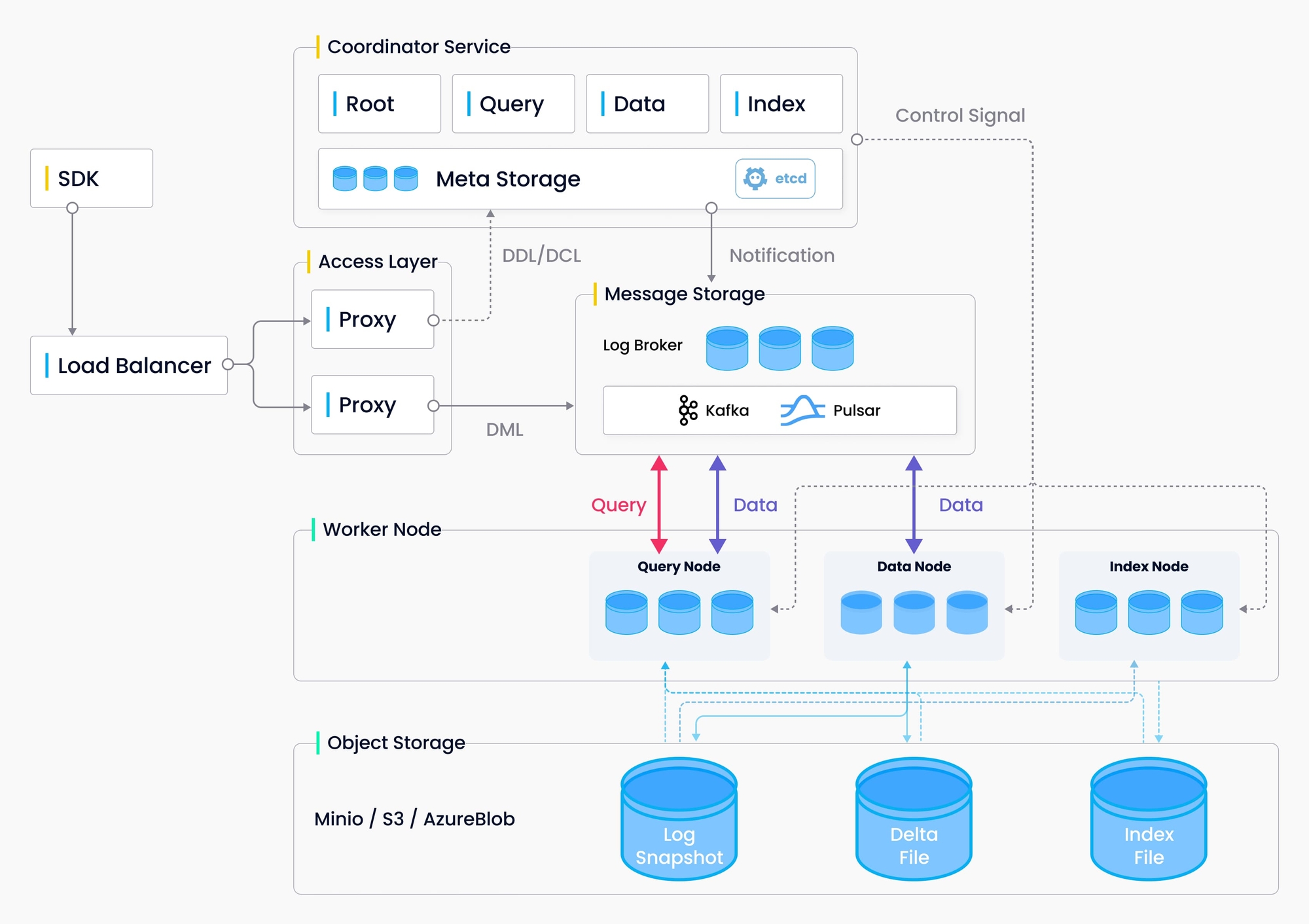
Milvus 的設計
作為一個原生雲端的向量資料庫,Milvus 分離了儲存和計算。為了增強彈性和靈活性,Milvus 中的所有組件都是無狀態的。系統分成 4 層:
- 存取層:存取層由一群無狀態的代理和伺服器組成,作為系統的前端層以及使用者的端點
- 協調服務:協調服務分配任務給工作節點和函式,角色是系統的大腦
- 工作節點:工作節點的角色是作為手腳,單純的執行者,只會遵循協調服務的指示執行用戶觸發的 DML/DDL 命令。
- 儲存:儲存是系統的骨幹,責任是資料的持久化。包含 Meta Storage 元數據、Log Broker 日誌代理、Object Storage 物件儲存
開發者工具
Milvus 支援豐富的 API 和工具。
API
Milvus 支援客戶端函式庫,支援 Milvus API 讓應用程式可以實作新增、刪除、查詢。
Milvus 工具
Milvus 生態圈提供輔助工具包含:
- Milvus CLI
- Attu Milvus 圖形化管理介面
- MilvusDM (Milvus Data Migration) 開源工具,用來匯入匯出 Milvus 資料
- Milvus sizing tool 協助評估指定數量向量在使用不同索引類型時所需的原始文件大小、記憶體大小和硬碟大小。
使用 Docker 安裝 Milvus 單機版
首先下載啟動腳本:
1 | $ wget https://raw.githubusercontent.com/milvus-io/milvus/master/scripts/standalone_embed.sh |
然後啟動 Milvus
1 | $ bash standalone_embed.sh start |
停止服務:
1 | $ bash standalone_embed.sh stop |
若要在停止 Milvus 後刪除資料
1 | $ bash standalone_embed.sh delete |
檢查服務是否啟用:
1 | $ docker ps |
或者使用 Docker 圖形介面確認容器是否啟動。
後續可以使用 cli 或圖形工具進行連線:
- Milvus CLI
- Attu Milvus 圖形化管理介面
除了單機版之外,還有 Milvus Lite 輕量版可以用於測試。
安裝 cli on macOS
前置作業 Python >= 3.8.5
1 | # 更新 Python 版本 |
安裝指令工具:
1 | $ pip install pymilvus==2.3.4 |